역시 사람은 똑똑하고 봐야...
지난 과정에서 파이널 프로젝트를 진행할 때, 네이버 뉴스 크롤링을 진행했다. 그 때 네이버 뉴스 검색 결과 페이지가 400페이지밖에 표시되지 않아서, 1) 월별로 마지막 페이지가 몇 페이지까지 있는지 검색한 뒤, 2) 마지막 페이지를 설정해 주었다. 프로젝트를 마무리한 뒤에도 이 부분을 (굳이) 일일이 검색하고 설정해 주어야 하나, 혹시 다른 해결책은 없나 궁금해 했었으나, 마땅한 방법을 찾지는 못했다.
그런데 이번에 NLP 과정에서 JK(네이버 뉴스 크롤링 담당)와 미니 프로젝트를 진행하며, JK가 재귀함수를 이용해 내가 궁금해 하던 부분을 간단하게 해결한 것을 보았다. 핵심은 재귀였다. 마지막 페이지까지 검색하는 법을 배웠다. 개인적으로 코딩 처음 배울 때부터 재귀가 너무 어려워서 백준 문제 풀 때에도 재귀 부분은 건너 뛰고 풀었는데, 재귀 함수를 이렇게 활용할 수 있다는 것을 처음 깨달았다. 더 열심히 공부해야겠다는 생각과 함께, 꼭 기억해 놓고 싶다는 생각에 JK의 허락을 얻어 기록한다. (JK 감사해...)
# 사용한 라이브러리
- requests
- BeatifulSoup
- urllib.parse : parse_qs, urlparse
- pandas, json, pprint, os
# 자료 저장할 딕셔너리 초기화
def dic_initialize(main_article_dic, comment_dic):
main_article_dic = {
'플랫폼': [],
'날짜': [],
'제목': [],
'내용': [],
'url': []
}
comment_dic = {
'url_origin': [],
'날짜': [],
'내용': []
}
return main_article_dic, comment_dic
# 댓글 데이터 크롤링
신윤수 강사님(ys@betweak.com)의 수업 때 네트워크 요청 및 response 분석을 통해 네이버 뉴스 댓글 데이터를 가져오는 방법을 배웠다. Selenium을 활용하지 않고도 댓글을 크롤링할 수 있었는데, JK가 활용했기에 (수업 내용도 정리할 겸) 다시 한 번 기록한다.
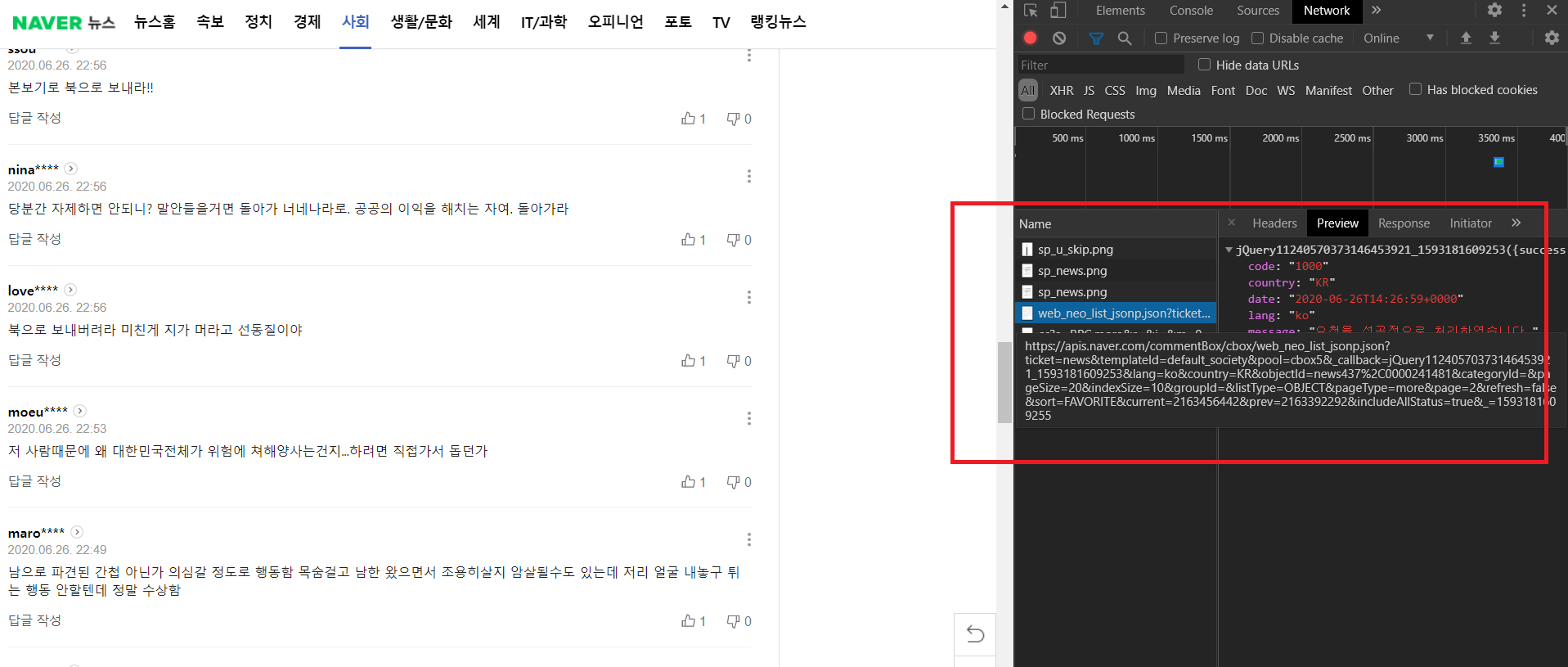
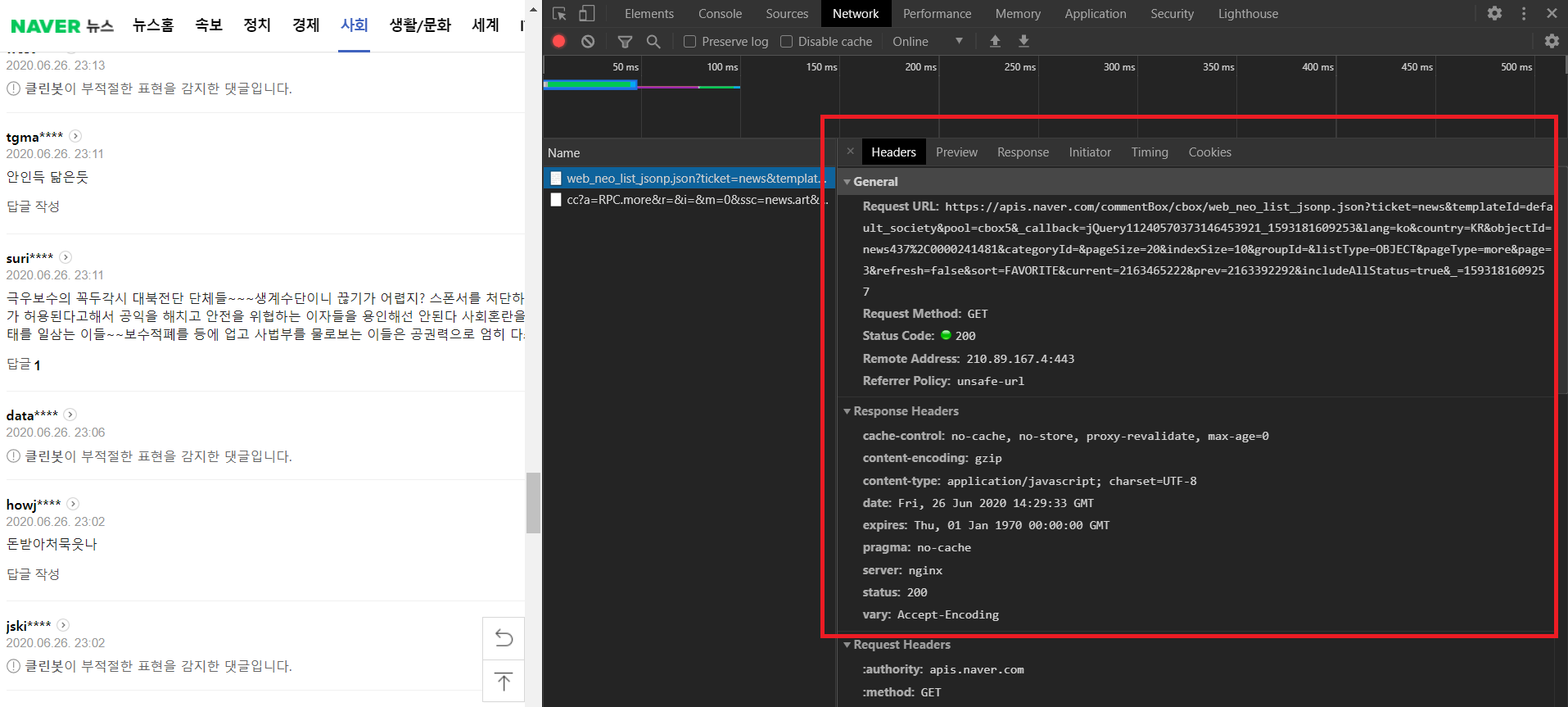
# comment 가져오기 위해 request GET 요청 보내는 함수
def comment_request(oid, aid, page, pageSize=100):
comment_base_url = 'https://apis.naver.com/commentBox/cbox/web_neo_list_jsonp.json?'
parmas = {
'ticket': 'news',
'templateId': 'default_it',
'pool': 'cbox5',
'lang': 'ko',
'country': 'KR',
'objectId': 'news{},{}'.format(oid, aid),
'pageSize': pageSize,
'indexSize': 10,
'listType': 'OBJECT',
'pageType': 'more',
'page': page,
'initialize': 'true',
'useAltSort': 'true',
'replyPageSize': 20,
'sort': 'favorite',
'cleanbotGrade': 2,
'includeAllStatus': 'true',
'_': '1591257986048'
}
headers = {
'referer': 'https://news.naver.com/main/read.nhn?m_view=1&includeAllCount=true&mode=LSD&mid=sec&sid1=105&oid={}&aid={}'.format(oid, aid)
}
return requests.get(comment_base_url, params=params, headers=headers)
위의 함수에서 GET 요청을 보내기 위해서는 동적으로 oid, aid를 제어해주어야 한다. 이를 위해 다음의 함수를 활용한다.
# 뉴스 url에서 oid, aid 추출
def getOidAid(url):
parsed_url = urlparse(url)
qs = parse_qs(parsed_url.query)
return qs['oid'][0], qs['aid'][0]
urlparse 함수는 ParseResult를 반환한다.
ParseResult(scheme='https', netloc='news.naver.com', path='/main/read.nhn', params='', query='m_view=1&includeAllCount=true&mode=LSD&mid=shm&sid1=102&oid=437&aid=0000241481', fragment='')
그 중에서 필요한 것이 'query'이기 때문에, ParseResult의 'query'에 접근한다. parse_qs 함수에 의해 쿼리셋을 분리하면 다음과 같은 dictionary가 반환된다.
{'aid': ['0000241481'], 'includeAllCount': ['true'], 'm_view': ['1'], 'mid': ['shm'], 'mode': ['LSD'], 'oid': ['437'], 'sid1': ['102']}
수업 들을 때도 종종 parse_qs에 의해 반환된 dictionary에 접근할 때 인덱싱하는 것을 잊었다. 주의하자.
요청을 보낸 후 댓글 데이터를 json 형태로 바꾸어 가져 온다.
# 더보기 comment를 json 데이터로 바꾸는 함수
def naver_resp_to_json(resp_text):
comment_text = resp_text[10:-2] # string data에서 필요 없는 부분 버리기
comment_resp_dict = json.loads(comment_text)
return comment_resp_dict
# 주어진 시간, 검색어에 따라 Soup 반환
JK 아이디어의 핵심이다. 주어진 기간 안에 기사가 몇 개 있는지 파악하고, 그 페이지 사이즈를 구한다. 그리고 페이지 수가 400이 넘으면, 기간을 반으로 나누어 다시 Soup 객체를 반환했다.
내가 짠 코드가 아니기 때문에, 아이디어만 어떻게 가져가고, 상세한 리뷰는 하지 않았다. 똑똑한 JK... 나는 옛날에 Selenium 써서 끝까지 넘길 생각만 했지, 이런 생각은 하지 못했다.
# 검색어, 년, 월에 따라 크롤링 후 저장
def getPeriodSoup(keyword, year, month, day_start, day_end):
paramsPage = []
news_main_url = 'https://search.naver.com/search.naver?'
params = {
'where': 'news',
'sm': 'tab_srt',
'sort': 2,
'query': keyword,
'start': 1,
'ds': '{}.{}.01'.format(str(year).zfill(2), str(month).zfill(2)),
'de': '{}.{}.31'.format(str(year).zfill(2), str(month).zfill(2)),
'pd': 3,
}
resp = requests.get(news_main_url, params=params)
soup = BeautifulSoup(resp.text)
# 주어진 기간 내 article 개수
total_article = int(''.join(soup.find('div', class_='title_desc all_my').\
.find('span').text.split('/')[1].strip()[:-1].split(',')))
total_article_page = total_article // 10 + 1
print(year, month, total_article, resp.url)
if total_article_page > 400 and day_start < (day_start + day_end) // 2:
# 반씩 나눠서 진행
paramsPage.extend(getPeriodSoup(keyword, year, month, day_start, (day_start + day_end)//2))
paramsPage.extend(getPeriodSoup(keyword, year, month, (day_start + day_end)//2 + 1, day_end
else:
# 한 번에 진행
paramsPage.append([params, total_article_page])
return paramsPage
'기타' 카테고리의 다른 글
| 어디다 기록할 지 몰라 여기로 온 Pandas 사용법 (0) | 2021.05.02 |
|---|---|
| [트위터 크롤링] GetOldTweets3 (22) | 2020.06.11 |
| [크롤링] TIL (0) | 2020.05.19 |