동적으로 변화하는 컨텐츠인 댓글을 크롤링하기 위해서는 Selenium을 이용해야 한다. 작업을 통해 얻고자 하는 결과물은 Selenium을 이용해 추출한 모든 네이버 뉴스 링크들의 뉴스 플랫폼, 제목, 작성 시간, 언론사, 댓글 작성자, 작성 시간, 댓글 내용, 댓글 공감/비공감 수이다.
# 사용한 라이브러리
- Requests
- Selenium
- BeautifulSoup,
- re, time, urllib.parse
# Selenium을 이용해 html 페이지 불러오기
웹 드라이버의 .page_source를 활용해 브라우저에 보이는 상태 그대로의 HTML을 가져온다. requests를 사용할 때와 달리, 웹 브라우저 엔진이 DOM이 바뀌는 상태를 기다릴 수 있도록 기다려야 한다. Selenium의 묵시적 대기로 1초 동안 기다리게 함으로써 댓글 페이지를 로드한다.
BeautifulSoup을 이용해 파싱하는 과정은 동일하다.
이전 단계의 작업에서와 달리, 기사를 어디서 가져왔는지 플랫폼의 출처도 정보로 가져오기로 했다. 이 기사들은 네이버 뉴스 플랫폼을 통해 제공되고, 내가 만든 크롤러가 돌아다니는 기사 댓글 페이지 링크에서는 'h1' 태그의 'span'에 NAVER 단어가 들어 있다.
하나의 테스트용 URL을 통해 각각의 정보를 가져올 수 있는지 확인한다.
from selenium import webdriver
test_url = "https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=101&oid=023&aid=0003518886&m_view=1"
driver = webdriver.Chrome("D:\python_DA\chromedriver.exe") # 드라이버 경로 설정
driver.implicitly_wait(1) # 1초간 기다리도록 설정
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
title = soup.find('h3', {'id':'articleTitle'}).get_text(strip=True)
article_time = soup.find('span', {'class':'t11'}).get_text(strip=True)
press = soup.find('div', {'class':"press_logo"}).find('a').find('img')['title']
확인 결과, 페이지에서 해당 정보를 잘 가져온다.
위를 참고해 기존의 extract_info 함수를 바꾸면 다음과 같다.
driver = webdriver.Chrome("D:\python_DA\chromedriver.exe")
def extract_info(url, wait_time = 1):
driver.implicitly_wait(wait_time)
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
site = soup.find('h1').find("span").get_text(strip=True) # 출처
title = soup.find('h3', {'id':'articleTitle'}).get_text(strip=True) # 제목
article_time = soup.find('span', {'class':'t11'}).get_text(strip=True) # 기사 작성시간
press = soup.find('div', {'class':"press_logo"}).find('a').find('img')['title'] # 언론사
return {'site':site, 'title':title, 'article_time':article_time, 'press':press}
# Selenium을 이용해 댓글 로드하기
댓글이 있는 기사 페이지는 이용자가 댓글을 작성하는지 여부에 따라 실시간으로 바뀌는 동적 페이지이다. 또한, 댓글이 많은 경우 한 페이지에 있는 댓글이 한 번에 보이지 않는다. 이 경우 '더보기' 버튼을 클릭해서 숨겨진 댓글을 읽을 수 있다. 모든 댓글을 추출하기 위해서는, 우선 한 페이지에 모든 댓글이 다 나와야 한다. 따라서 모든 댓글을 볼 수 있도록 웹 드라이버의 .click 메서드를 활용해 '더보기' 버튼을 계속해서 클릭한다.
- 웹 드라이버가 바로 '더보기' 버튼을 찾도록 한다.
- '더보기' 버튼은 class가 'u_cbox_btn_more'인 a 태그이다.
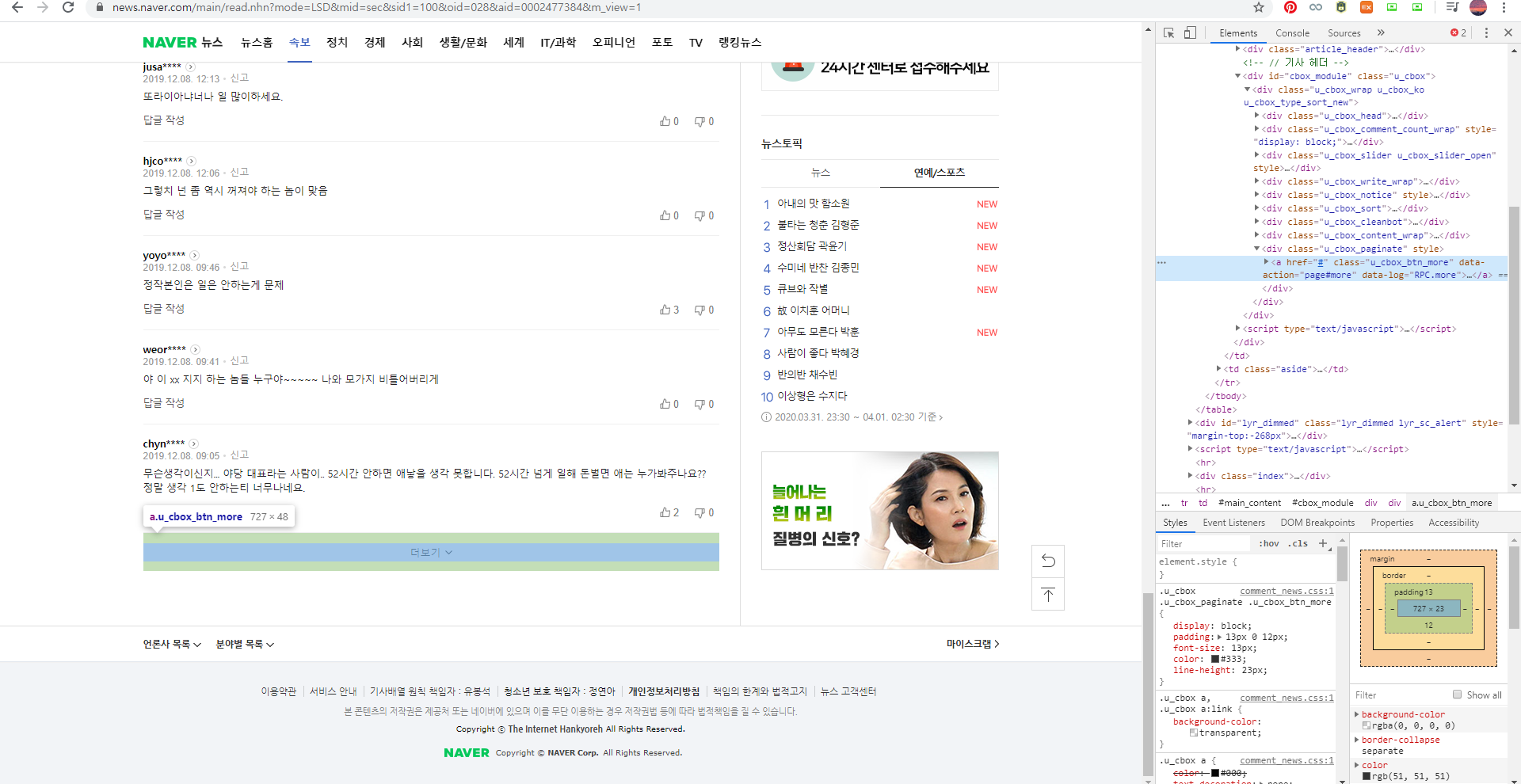
- '더 보기' 버튼이 없는 경우 에러(AttributeError)가 난다. 이를 해결하기 위해 try, except 구문을 사용한다.
- click 후에는 코드 실행을 잠시 지연시켜서 아래의 댓글이 로드될 수 있도록 기다린다.
테스트를 위해 검색 결과의 3페이지까지만 네이버 뉴스 링크를 찾고, '더보기' 버튼을 클릭하도록 코드를 짰다.
import time
naver_news_links = get_news_link(3, LINK_PAT) # 테스트를 위해 3페이지까지만 링크 가져온다.
driver = webdriver.Chrome("D:\python_DA\chromedriver.exe")
for link in naver_news_links:
driver.implicitly_wait(1)
driver.get(link)
while True:
try:
more_comments = driver.find_element_by_css_selector('a.u_cbox_btn_more')
more_comments.click()
time.sleep(0.3)
except:
break
브라우저가 잘 열리고, '더 보기' 버튼을 누르는 것을 확인할 수 있다.
이를 함수화하여 기존의 extract_info 함수를 변경하면 다음과 같다.
# module import
from selenium import webdriver
import time
# Selenium을 이용해 정보 추출
def extract_info(url, wait_time=1, delay_time=0.3):
driver.implicitly_wait(wait_time)
driver.get(url)
# 댓글 창 있으면 다 내리기
while True:
try:
more_comments = driver.find_element_by_css_selector('a.u_cbox_btn_more')
more_comments.click()
time.sleep(delay_time)
except:
break
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
site = soup.find('h1').find("span").get_text(strip=True)
title = soup.find('h3', {'id':'articleTitle'}).get_text(strip=True)
article_time = soup.find('span', {'class':'t11'}).get_text(strip=True)
press = soup.find('div', {'class':"press_logo"}).find('a').find('img')['title']
return {'site':site, 'title':title, 'article_time':article_time, 'press':press}
# Selenium을 이용해 댓글 정보 추출하기
이제 댓글에서 얻어야 할 모든 정보를 추출하기만 하면 된다. 테스트를 위해 하나의 예시 URL에 들어가 selenium으로 댓글 페이지를 로드하고, 작성자와 댓글 내용, 작성 시간, 공감/비공감 수를 가져와 본다.
댓글 관련 정보를 가져오는 데에 두 가지 방법이 있다.
- find_all을 통해 댓글 작성자, 내용 등에 해당하는 모든 요소들을 리스트에 저장한 뒤, 순서에 맞게 하나씩 묶어 다른 배열에 저장한다. 이 경우, 각 정보들은 다음의 태그를 통해 찾을 수 있다.
- 댓글 작성자 : class가 'u_cbox_nick'인 'span' 태그.
- 댓글 내용 : class가 'u_cbox_contents'인 'span' 태그.
- 댓글 작성 시간 : class가 'u_cbox_date'인 'span' 태그.
- 공감/비공감 : class가 각각 'u_cbox_cnt_recomm'과 'u_cbox_cnt_unrecomm'인 'em' 태그.
- find_all을 통해 하나의 댓글이 단위로 들어 있는 class가 'u_cbox_area'인 div 태그를 모두 찾아 리스트에 저장한다. 리스트의 각 요소들에 대해 댓글 작성자, 댓글 내용, 댓글 작성 시간, 공감/비공감을 찾는다.
 |
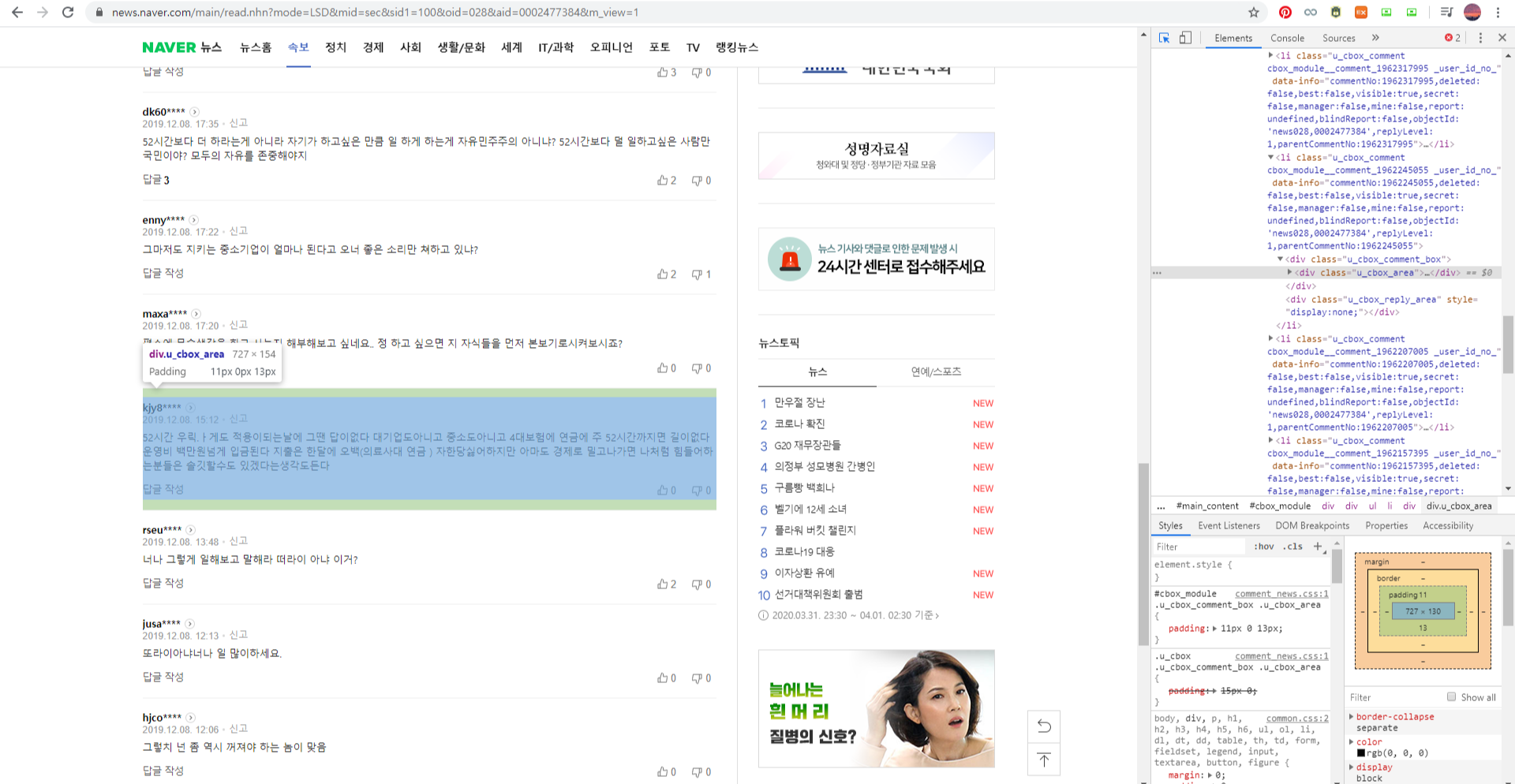 |
아래는 오른쪽 방법으로 하나의 테스트용 URL에 들어가서 정보를 추출한 코드이다.
test_url = "https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=101&oid=023&aid=0003518886&m_view=1"
driver = webdriver.Chrome("D:\python_DA\chromedriver.exe")
driver.implicitly_wait(5)
driver.get(test_url)
while True:
try:
more_comments = driver.find_element_by_css_selector('a.u_cbox_btn_more')
more_comments.click()
time.sleep(5)
except:
break
html = driver.page_source
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
divs = soup.find_all("div", {"class":"u_cbox_area"})
for div in divs:
rep_nick = div.find("span", {"class" : "u_cbox_nick"}).get_text(strip=True) # 작성자
rep_time = div.find("span", {"class" : "u_cbox_date"}).get_text(strip=True) # 작성 시간
try: # 댓글 내용, 공감 수, 비공감 수
rep_comment = div.find("span", {"class" : "u_cbox_contents"}).get_text(strip=True)
rep_recom = int(div.find("em", {"class" : "u_cbox_cnt_recomm"}).get_text(strip=True))
rep_unrecomm = int(div.find("em", {"class" : "u_cbox_cnt_unrecomm"}).get_text(strip=True))
except:
rep_comment = np.nan
rep_recom = np.nan
rep_unrecomm = np.nan
print({'닉네임' : rep_nick, '작성 시간' : rep_time, '공감' : rep_recom, '댓글' : rep_comment})
정보가 잘 추출되기는 하지만, div 태그를 찾고, 또 그 안에서 각각의 태그를 찾아야 하며, 예외 처리도 해주어야 하기 때문에 좋은 코드라는 생각은 들지 않는다.
왼쪽 방법을 사용해 함수로 만들면 다음과 같다.
from selenium import webdriver
import time
# 한 페이지 별로 필요한 정보 스크레이핑
def extract_info(url, wait_time=1, delay_time=0.3):
driver.implicitly_wait(wait_time)
driver.get(url)
# 댓글 창 있으면 다 내리기
while True:
try:
more_comments = driver.find_element_by_css_selector('a.u_cbox_btn_more')
more_comments.click()
time.sleep(delay_time)
except:
break
# html 페이지 읽어오기
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
site = soup.find('h1').find("span").get_text(strip=True) # 출처
title = soup.find('h3', {'id':'articleTitle'}).get_text(strip=True) # 기사 제목
article_time = soup.find('span', {'class':'t11'}).get_text(strip=True) # 작성 시간
press = soup.find('div', {'class':"press_logo"}).find('a').find('img')['title'] # 언론사
reply = [] # 댓글 내용 취합
total_com = soup.find("span", {"class" : "u_cbox_info_txt"}).get_text() # 댓글 수
nicks = soup.find_all("span", {"class":"u_cbox_nick"}) # 댓글 작성자
nicks = [nick.text for nick in nicks]
dates = soup.find_all("span", {"class":"u_cbox_date"}) # 댓글 날짜
dates = [date.text for date in dates]
contents = soup.find_all("span", {"class":"u_cbox_contents"}) # 댓글 내용
contents = [content.text for content in contents]
recomms = soup.find_all("em", {"class":"u_cbox_cnt_recomm"}) # 공감 수
recomms = [recomm.text for recomm in recomms]
unrecomms = soup.find_all("em", {"class":"u_cbox_cnt_unrecomm"}) # 비공감수
unrecomms = [unrecomm.text for unrecomm in unrecomms]
# 각각의 요소 리스트에 추가
for i in range(len(contents)):
reply.append({'nickname':nicks[i],
'date':dates[i],
'contents':[i],
'recomm':recomms[i],
'unrecomm':unrecomms[i]})
print("완료") # 확인용
return {'site':site, 'title':title, 'article_time':article_time, 'press':press, 'total_comments':total_com, 'reply_content':reply}
이 단계에서의 작업을 모두 정리하면 다음과 같다.
main 함수에서 driver를 닫는 작업이 포함되었다.
# module import
import requests
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
import numpy as np
import csv
# 변수 설정
QUERY = "주52시간"
search_QUERY = urllib.parse.urlencode({'query':QUERY}, encoding='utf-8')
URL = f"https://search.naver.com/search.naver?&where=news&{search_QUERY}\
&sm=tab_pge&sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&mynews=0"
LINK_PAT = "https:\/\/news\.naver\.com\/main\/read\.nhn\?"
# driver 설정
driver = webdriver.Chrome("D:\python_DA\chromedriver.exe")
# 마지막 페이지 호출 : 나중에 변경 방법 생각해 보기
def get_last_page():
req = requests.get(URL)
soup = BeautifulSoup(req.text, 'lxml')
pagination = soup.find('div', {'class' : 'paging'})
pages = pagination.find_all("a")
page_list = []
for page in pages[1:-1]:
page_list.append(int(page.get_text(strip = True)))
max_page = page_list[-1]
return max_page
# 검색결과 내 링크 찾기 : news.naver.com으로 시작하는 모든 링크 반환
def get_news_links(page_num, link_pattern):
links = []
for page in range(page_num):
print(f"Scrapping page : {page+1}") # 확인용
req = requests.get(f"{URL}&start={10*page+1}"); print(req.status_code)
soup = BeautifulSoup(req.text, 'lxml')
results = soup.find_all('a', {'href' : re.compile(link_pattern)})
for result in results:
links.append(result['href'])
print(f"총 {len(links)}개의 뉴스 링크를 찾았습니다.") # 확인용
return links
# 한 페이지 별로 필요한 정보 스크레이핑
def extract_info(url, wait_time=1, delay_time=0.3):
driver.implicitly_wait(wait_time)
driver.get(url)
# 댓글 창 있으면 다 내리기
while True:
try:
more_comments = driver.find_element_by_css_selector('a.u_cbox_btn_more')
more_comments.click()
time.sleep(delay_time)
except:
break
# html 페이지 읽어오기
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
# 출처
site = soup.find('h1').find("span").get_text(strip=True)
# 기사 제목
title = soup.find('h3', {'id':'articleTitle'}).get_text(strip=True)
# 작성 시간
article_time = soup.find('span', {'class':'t11'}).get_text(strip=True)
# 언론사
press = soup.find('div', {'class':"press_logo"}).find('a').find('img')['title']
# 댓글 수
total_com = soup.find("span", {"class" : "u_cbox_info_txt"}).get_text()
# 댓글 작성자
nicks = soup.find_all("span", {"class":"u_cbox_nick"})
nicks = [nick.text for nick in nicks]
# 댓글 날짜
dates = soup.find_all("span", {"class":"u_cbox_date"})
dates = [date.text for date in dates]
# 댓글 내용
contents = soup.find_all("span", {"class":"u_cbox_contents"})
contents = [content.text for content in contents]
# 공감 수
recomms = soup.find_all("em", {"class":"u_cbox_cnt_recomm"})
recomms = [recomm.text for recomm in recomms]
# u_cbox_cnt_unrecomm
unrecomms = soup.find_all("em", {"class":"u_cbox_cnt_unrecomm"})
unrecomms = [unrecomm.text for unrecomm in unrecomms]
# 취합
# replys = list(zip(nicks, dates, contents)) # tuple형태
reply = []
for i in range(len(contents)):
reply.append({'nickname':nicks[i],
'date':dates[i],
'contents':contents[i],
'recomm':recomms[i],
'unrecomm':unrecomms[i]})
print("완료") # 확인용
return {'site':site, 'title':title, 'article_time':article_time, 'press':press, 'total_comments':total_com, 'reply_content':reply}
# 각 페이지 돌면서 스크레이핑
def extract_contents(links):
contents = []
for link in links:
content = extract_info(f"{link}&m_view=1") # 각각의 링크에 대해 extract_info 함수 호출
contents.append(content) # extract_info의 결과로 나오는 dict 저장
return contents
# main 함수
def main():
last_page = get_last_page() # 마지막 페이지
news_links = get_news_links(last_page, LINK_PAT)
result = extract_comments(news_links)
driver.quit()
return result
'AI > 정책 댓글 반응 NLP' 카테고리의 다른 글
| [1] 네이버 뉴스 댓글 크롤러_ver1.5_검색페이지 확대 (0) | 2020.04.01 |
|---|---|
| [1] 네이버 뉴스 댓글 크롤러_ver1_4. 데이터 저장 및 마무리 (0) | 2020.04.01 |
| [1] 네이버 뉴스 댓글 크롤러_ver1_2. 각 기사 링크 페이지에 접속해 정보 가져오기 (0) | 2020.04.01 |
| [1] 네이버 뉴스 댓글 크롤러_ver1_1. 네이버 뉴스 링크 반환 (0) | 2020.04.01 |
| [1] 네이버 뉴스 댓글 크롤러_ver1_0.사전 작업 (0) | 2020.03.31 |