이번 단계의 작업에서는 이전 단계의 작업에서 찾아낸 문제점을 위주로 코드를 수정한다. 작업을 통해 얻고자 하는 결과물은 크롤러가 직접 MLBPARK 불펜에서 '주52시간'을 검색하여 찾아낸 마지막 페이지 범위까지의 게시물들 중, 커뮤니티 이름(MLBPARK), 글 제목, 글 작성 시간, 글 작성자, 추천 수, 조회 수, 댓글 수, 댓글 내용이다.
# 사용한 라이브러리
- Requests
- Selenium
- time
- BeautifulSoup
- urllib.parse
- csv
# 데이터 추출 코드 수정
첫 번째로, 조회 수와 추천 수가 똑같다는 문제를 해결했다. 기존에 내 코드가 선택한 부분은 파란 음영이 칠해진 부분(..!)이었다. 선택해야 하는 부분은 빨간색 상자 부분이다.

조회수 정보를 담은 태그를 찾기 위해, class가 'text2'인 'div' 태그의 'span' 태그들을 모두 찾았다. 그러자, 조회, 1584, 리플, 4가 나오는 것을 볼 수 있다. 인덱싱을 이용해 1584만 선택하고, ','를 삭제한 뒤, 정수형으로 바꿔주었다.
두 번째로, 댓글을 저장하기 전 '\r', '\t', '\n'을 삭제했다.
세 번째로, 글 작성 시간을 포함하고, 시간 형식을 'YY-MM-DD HH:MM:SS'으로 바꿔줬다. 이전 단계의 작업에서 모르고 글 작성 시간을 저장하지 않았다. MLBPARK에는 글 작성 시간이 초 단위까지 나오지 않기 때문에, 데이터 통일을 위해 임의로 시간 뒤에 ":00"을 붙여준 뒤, datetime 모듈을 이용해 변환했다.
모든 작업을 진행한 뒤 수정한 함수는 다음과 같다.
# 한 페이지에서 정보 가져오기
def extract_info(url, wait_time=3, delay_time=1):
driver = webdriver.Chrome("C:/Users/user/PycharmProjects/Scraping/chromedriver.exe")
driver.implicitly_wait(wait_time)
driver.get(url)
html = driver.page_source
time.sleep(delay_time) # 강제 연결 종료 방지
driver.quit()
soup = BeautifulSoup(html, 'lxml')
site = soup.find('h1', {'class': 'logo'}).find('a').find('img')['title'].strip()
title = soup.find('div', {'class': 'titles'}).get_text(strip=True)
user_id = soup.find('span', {'class': 'nick'}).get_text(strip=True)
post_time = soup.find('div', {'class':'text3'}).find('span', {'class':'val'}).get_text(strip=True) +":00" # datetime 형식으로 바꾸기 위해 초 추가.
post_time = dtime.strptime(post_time, '%Y-%m-%d %H:%M:%S')
post = soup.find('div', {'id': 'contentDetail'}).get_text(strip=True)
view_cnt = soup.find('div', {'class':'text2'}).find_all('span', {'class' :'val'})[1].get_text(strip=True) # 조회 수 선택자 변경.
view_cnt = int(view_cnt.replace('\n', '').replace('\r', '').replace(',', ''))
recomm_cnt = soup.find('span', {'id': 'likeCnt'}).get_text(strip=True)
recomm_cnt = int(recomm_cnt.replace('\n', '').replace('\r', '').replace(',', ''))
reply_cnt = soup.find('span', {'id': 'replyCnt'}).get_text(strip=True)
reply_cnt = int(reply_cnt.replace('\n', '').replace('\r', '').replace(',', ''))
reply_content = []
if reply_cnt != 0:
replies = soup.find_all('span', {'class': 're_txt'})
for reply in replies:
reply = reply.get_text(strip=True)
reply = reply.replace('\n', '').replace('\r', '').replace('\t','')
reply_content.append(reply)
reply_content = '\n'.join(reply_content)
print(url, " 완료")
return {'site': site, 'title': title, 'user_id': user_id, 'post_time':post_time, 'post': post, 'view_cnt': view_cnt, 'recomm_cnt': recomm_cnt, 'reply_cnt': reply_cnt, 'reply_content': reply_content}
# 파일 생성 후, 한 줄 씩 쓰도록 수정
기존의 코드는 한 번에 모든 크롤링 작업을 완료하고, 한 번에 csv 파일을 저장했다. 그런데 이와 같이 작업을 진행할 경우, 크롤링해야 할 데이터가 많아질 때, (사실 지금만 하더라도 1462개의 글을 돌아다녀야 하는데, 중간에 오류가 나면 이전까지의 작업물을 저장할 수 없다.) 문제가 될 것이라 판단했다.
따라서 작업을 시작할 때 저장할 파일을 만들고, 데이터를 스크레이핑해오면서 그것을 리스트에 저장하는 것이 아니라, 생성한 파일을 열어 한 행씩 데이터를 추가하도록 했다. 파일 열기 모드만 'a'로 바꿔주면 된다.
위의 과정에 따라 수정한 코드는 다음과 같다. get_contents() 함수가 리스트에 결과를 append하지 않고, append_to_file() 함수를 호출해서 기존의 파일에 새로이 찾은 내용을 추가한다.
# 저장 파일 만드는 함수
def save_to_file():
global QUERY
global PAGES
file = open(f"MLBPARK_{QUERY}_{PAGES}pages_checkiferror.csv", mode='w', encoding='utf-8')
writer = csv.writer(file)
writer.writerow(['site', 'title', 'user_id', 'post_time', 'post', 'view_cnt', 'recomm_cnt', 'reply_cnt', 'reply_content'])
file.close()
return file
# 게시글 링크 가져오기
def get_posts():
global QUERY
global PAGES
board_links = get_boards(PAGES)
posts = []
for board_link in board_links:
# print(f"게시판 링크는 {board_link}")
req = requests.get(board_link)
print(req.status_code) # 49개 나와야 함
soup = BeautifulSoup(req.text, 'lxml')
tds = soup.find_all('td', {'class': 't_left'})
for td in tds:
post = td.find('a', {'class': 'bullpenbox'})
if post is not None:
posts.append(post['href'])
print(f"총 {len(posts)}개의 글 링크를 찾았습니다.")
# 게시글 링크 csv로 저장
post_file = open(f"MLBPARK_{QUERY}_{PAGES}pages_inner_links.csv", mode='w', encoding='utf-8')
writer = csv.writer(post_file)
for post in posts:
writer.writerow([post])
post_file.close()
return posts
# 파일 열어서 쓰는 함수
def append_to_file(file_name, dictionary):
file = open(file_name, mode='a', encoding='utf-8') # 덮어 쓰기
writer = csv.writer(file)
writer.writerow(list(dictionary.values()))
file.close()
return
# 모든 게시물 링크에 대해 정보 가져오는 함수 호출
def get_contents():
global mlbpark_results
post_links = get_posts()
for post_link in post_links:
content = extract_info(post_link)
append_to_file(f"MLBPARK_{QUERY}_{PAGES}pages.csv", content)
return print("모든 작업이 완료되었습니다.")
모든 작업을 한 번에 진행한 코드는 다음과 같다.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlencode
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
import time
from datetime import datetime as dtime
import csv
# 변수 설정
QUERY = "주52시간"
search_QUERY = urlencode({'query' : QUERY}, encoding = 'utf-8')
URL = f"http://mlbpark.donga.com/mp/b.php?select=sct&m=search&b=bullpen&select=sct&{search_QUERY}&x=0&y=0"
# 마지막 페이지까지 클릭
def go_to_last_page(url):
options = Options()
ua = UserAgent()
userAgent = ua.random
print(userAgent)
options.add_argument(f'user-agent={userAgent}')
driver = webdriver.Chrome(chrome_options=options,
executable_path='C:/Users/user/PycharmProjects/Scraping/chromedriver.exe')
driver.get(url)
wait = WebDriverWait(driver, 10)
while True:
# class가 right인 버튼이 없을 때까지 계속 클릭
try:
time.sleep(5)
element = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'right')))
element.click()
time.sleep(5)
except TimeoutException:
print("no pages left")
break
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
driver.quit()
return soup
# 마지막 페이지 번호 알아내기
def get_last_page(url):
soup = go_to_last_page(url)
pagination = soup.find('div', {'class' : 'page'})
pages = pagination.find_all("a")
page_list = []
for page in pages[1:]:
page_list.append(int(page.get_text(strip=True)))
max_page = page_list[-1]
print(f"총 {max_page}개의 페이지가 있습니다.")
return max_page
# 게시판 링크 모두 가져오기
def get_boards(page_num):
boards = []
for page in range(page_num):
boards.append(f"http://mlbpark.donga.com/mp/b.php?p={30*page+1}&m=search&b=bullpen&{search_QUERY}&select=sct&user=")
return boards
# 게시글 링크 가져오기
def get_posts():
global QUERY
global PAGES
board_links = get_boards(PAGES)
posts = []
for board_link in board_links:
# print(f"게시판 링크는 {board_link}")
req = requests.get(board_link)
print(req.status_code) # 49개 나와야 함
soup = BeautifulSoup(req.text, 'lxml')
tds = soup.find_all('td', {'class': 't_left'})
for td in tds:
post = td.find('a', {'class': 'bullpenbox'})
if post is not None:
posts.append(post['href'])
print(f"총 {len(posts)}개의 글 링크를 찾았습니다.")
# 게시글 링크 csv로 저장
post_file = open(f"MLBPARK_{QUERY}_{PAGES}pages_inner_links.csv", mode='w', encoding='utf-8')
writer = csv.writer(post_file)
for post in posts:
writer.writerow([post])
post_file.close()
return posts
# 한 페이지에서 정보 가져오기
def extract_info(url, wait_time=3, delay_time=1):
driver = webdriver.Chrome("C:/Users/user/PycharmProjects/Scraping/chromedriver.exe")
driver.implicitly_wait(wait_time)
driver.get(url)
html = driver.page_source
time.sleep(delay_time) # 강제 연결 종료 방지
driver.quit()
soup = BeautifulSoup(html, 'lxml')
site = soup.find('h1', {'class': 'logo'}).find('a').find('img')['title'].strip()
title = soup.find('div', {'class': 'titles'}).get_text(strip=True)
user_id = soup.find('span', {'class': 'nick'}).get_text(strip=True)
post_time = soup.find('div', {'class':'text3'}).find('span', {'class':'val'}).get_text(strip=True) +":00" # datetime 형식으로 바꾸기 위해 초 추가.
post_time = dtime.strptime(post_time, '%Y-%m-%d %H:%M:%S')
post = soup.find('div', {'id': 'contentDetail'}).get_text(strip=True)
view_cnt = int(soup.find('div', {'class':'text2'}).find_all('span', {'class' :'val'})[1].get_text(strip=True).replace('\n', '').replace('\r', '').replace(',', ''))
recomm_cnt = int(soup.find('span', {'id': 'likeCnt'}).get_text(strip=True).replace('\n', '').replace('\r', '').replace(',', ''))
reply_cnt = int(soup.find('span', {'id': 'replyCnt'}).get_text(strip=True).replace('\n', '').replace('\r', '').replace(',', ''))
reply_content = []
if reply_cnt != 0:
replies = soup.find_all('span', {'class': 're_txt'})
for reply in replies:
reply_content.append(reply.get_text(strip=True).replace('\n', '').replace('\r', '').replace('\t',''))
reply_content = '\n'.join(reply_content)
print(url, " 완료")
return {'site': site, 'title': title, 'user_id': user_id, 'post_time':post_time, 'post': post, 'view_cnt': view_cnt, 'recomm_cnt': recomm_cnt, 'reply_cnt': reply_cnt, 'reply_content': reply_content}
# 모든 게시물 링크에 대해 정보 가져오는 함수 호출
def get_contents():
global mlbpark_results
post_links = get_posts()
for post_link in post_links:
content = extract_info(post_link)
append_to_file(f"MLBPARK_{QUERY}_{PAGES}pages.csv", content)
return print("모든 작업이 완료되었습니다.")
# 저장 파일 만드는 함수
def save_to_file():
global QUERY
global PAGES
file = open(f"MLBPARK_{QUERY}_{PAGES}pages.csv", mode='w', encoding='utf-8')
writer = csv.writer(file)
writer.writerow(['site', 'title', 'user_id', 'post_time', 'post', 'view_cnt', 'recomm_cnt', 'reply_cnt', 'reply_content'])
file.close()
return file
# 파일 열어서 쓰는 함수
def append_to_file(file_name, dictionary):
file = open(file_name, mode='a', encoding='utf-8') # 덮어 쓰기
writer = csv.writer(file)
writer.writerow(list(dictionary.values()))
file.close()
return
# 함수 실행
PAGES = get_last_page(URL)
mlbpark_results = save_to_file()
get_contents()
# 데이터 확인
작업을 통해 다음의 결과를 얻었다.
데이터를 확인한 결과는 다음과 같다.

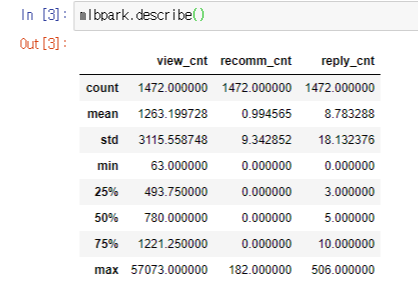
수치형 데이터의 요약 통계량을 확인했다. 이전과 달리 1472개의 게시물이 모두 저장되었고, 조회수에 있었던 문제도 잘 해결되었다.
# 데이터 기초 전처리
글 제목에 말머리가 표시되었다. MLBPARK 커뮤니티에 가입해 글쓰기 버튼을 누른 뒤, 선택할 수 있는 말머리가 몇 가지가 있는지 확인했다. 이후 혹시 확인하지 못한 말머리가 있을 수도 있어 글 제목에서 2글자, 3글자, 4글자씩 늘려가며 데이터에 있는 말머리를 확인했고, 제거했다.
이후 댓글에 있는 carriage return('\r'), tab('\t') 등의 문자를 제거했다.
작업을 진행한 코드는 다음과 같다.
headers = ['정치', '경제', '사회', '문화', '코인', '음악', '연예', '방송', '게임',
'뻘글', '후기', '채팅', '짤방', '단문', '펌글', '질문', '응원',
'키움', '두산', '롯데', '삼성', '한화', 'kt', 'LG', 'NC', 'SK',
'스포츠', '아이돌', 'LOL', '19금', '17금', 'COB', '주번나', 'KIA', 'KBO', '[펌]'
'개선요청', '아마야구']
def cleanseTitle(df, colname, lst):
for i in range(len(df)):
if df[colname][i][:2] in lst:
df[colname][i] = df[colname][i][2:]
if df[colname][i][:3] in lst:
df[colname][i] = df[colname][i][3:]
if df[colname][i][:4] in lst:
df[colname][i] = df[colname][i][4:]
return df
cleanseTitle(mlbpark, 'title', headers)
def cleanseCharacters(df, colname, character):
df[colname] = df[colname].str.replace(character, '')
return df
cleanseCharacters(mlbpark, 'reply_content', '\r')
cleanseCharacters(mlbpark, 'reply_content', '\t')
# 데이터 확인
정리한 데이터를 확인했다. 위에서 기초통계량을 확인하며 추천수, 댓글 수에 비해 조회수의 데이터 분포 편차가 크다는 것을 보고, 조회수가 많으면 추천과 댓글도 많을지, 댓글이 많이 달렸으면 조회수와 추천도 많을지 확인해 봤다.
우선, 조회수가 높은 순서대로 데이터를 정렬했다.

최대 추천수가 182였다는 것을 감안하면, 추천수가 높은 편에 속하는(130, 176, 177, 182) 게시물이 들어가 있다. 다만 추천수가 한 자리 수인 게시물도 많이 포함되어 있다. 조회수와 추천수의 관계를 속단하기는 이르다. 하지만, 조회수가 높으면서 추천수가 높다는 것은 그만큼 유저들에게 '추천할 만한 글'이라는 인상을 주었으며, 실제 그만큼 조회도 많이 이루어진 것으로 파악할 수 있다.
특히 897번째 데이터와 같이 조회수, 추천수, 댓글수 모두 많은 게시물은 추천을 많이 받을 만큼 글 내용도 좋았고, 글을 통해 사람들이 댓글을 달도록 의견을 이끌어 내는 공론장 역할을 했다고 볼 수 있다.
다음으로, 댓글 수가 높은 순서대로 데이터를 정렬했다.

댓글이 많이 달렸을수록 조회 수도 높아 보인다. 일단 댓글이 많다는 것 자체가 유저들이 조회를 많이 했고, 그만큼 댓글을 활발히 달아야 가능한 것이다. 이렇게 본다면, 댓글 수와 조회수는 높지만 추천 수가 별로 없는 게시물들의 경우, 자극적인 글 내용을 통해 논쟁을 유발하였으나, 유저들에게 '추천할 만한' 인상은 주지 못한 글이라고 판단할 수 있다.
댓글수, 조회수, 추천수 간 상관계수를 구해봤더니, 모두 0.65 이상으로 양의 상관관계를 가지고 있는 것으로 판단할 수 있다. 그중에서도 역시, 댓글의 수와 조회수의 상관관계가 가장 강했다.

이를 통해, 나중에 조회수, 추천수, 댓글수가 모두 높은 공통적인 게시물(545, 515, 897, 838번째 데이터)를 확인해 보고 싶다는 생각을 했다.
'AI > 정책 댓글 반응 NLP' 카테고리의 다른 글
| [1] 네이버 뉴스 댓글 크롤러_ver2 (3) | 2020.04.06 |
|---|---|
| [1] 커뮤니티 게시물 크롤러_2. 루리웹닷컴 (0) | 2020.04.06 |
| [1] 커뮤니티 게시물 크롤러_1. MLBPARK_1. 데이터 적재 (0) | 2020.04.03 |
| [1] 커뮤니티 게시물 크롤러_1. MLBPARK_0. 사전 작업 (4) | 2020.04.03 |
| [1] 네이버 뉴스 댓글 크롤러_ver1.5_검색페이지 확대 (0) | 2020.04.01 |