2019년 1월부터 2020년 3월까지의 데이터를 가지고 2020년 4월, 7월의 데이터를 예측하는 문제이기 때문에, 시계열 모델을 만들어 보았다. 이 모델을 활용해 결측치 채우는 방법, feature engineering 방식 등을 변경해 가며 다양한 경우를 시도해 본다.
# 데이터 준비
1. 곱연산 템플릿 만들기
대회 주최 측에서 제공한 데이터는 이미 각 feature(년월, 카드 이용지역, 업종, 고객 거주지역, 연령대, 성별, 가구생애주기)별로 집계된 AMT(이용금액), CSTMR_CNT(이용고객), CNT(이용건수)이다. 데이터를 이해할 때부터 힘들었던 부분이기도 한데, 각 feature별로 합계를 집계했을 때 합이 0이면, 즉, 해당하는 데이터가 없으면 제공된 데이터에 들어있지 않다. 전부 결측치라는 의미다.
시계열 모델을 만들기 위해서는 2019년 1월부터 2020년 3월, 각 feature별로 해당하는 데이터가 모두 있어야 하기 때문에 각 feature별로 모두 곱연산을 한 템플릿을 만들었다. 특별히 Feature Engineering을 진행하지는 않고, Baseline에서 진행한 것처럼 일단 결측치가 있는 열만 삭제했다. 그리고 남은 각각의 feature에서 unique한 레코드의 개수를 나타내면 다음과 같다.
| REG_YYMM | 15 |
| CARD_SIDO_NM | 17 |
| STD_CLSS_NM | 41 |
| HOM_SIDO_NM | 17 |
| AGE | 7 |
| SEX_CTGO_NM | 2 |
| FLC | 5 |
해당하는 경우에 대해 모두 곱연산을 해서 2019년 1월부터 2020년 3월까지 템플릿을 만들었다. 총 1200만 개가 넘는 행(정확히는 12441450개)(...)이 나온다.
주어진 데이터를 같은 방식으로 집계했을 때, 총 1057394개의 행이 나온다. 다시 말해, 총 1200만 개의 unique 레코드 중 예측해야 할 AMT 데이터가 있는 행은 100만 개 정도 뿐이다.
2. AMT 결측치 채우기
1100만 개 정도의 AMT 결측치를 어떻게든 채워야 시계열 모형을 만들 수 있다. 우선 가지고 있는 AMT 데이터의 최솟값이 800, 최댓값이 34925518737이기 때문에, 스케일 조정이 필요하다. (Baseline에서도 AMT에 log를 취해 예측했다.)
기본적으로 log를 취해 모델을 만들 것이라 가정하고, AMT의 결측치를 1, 10, 100, 1000 등 10의 거듭제곱 수로 채워 넣었을 때 AMT 값의 boxplot, 전체 범위가 어떻게 변하는지 확인하며 적당한 수를 찾고자 한다.
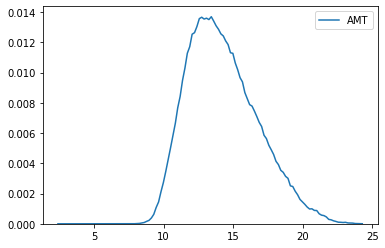
Baseline 용도이므로, 결측치를 10으로 채우기로 했다. 결측치를 10으로 채운 후 log1p 함수를 이용해 자연로그를 취한 값을 확인하면 다음과 같다. (log1p 함수의 특성 상, 진수가 0일 경우 1을 더한 값으로 변환해 준다.)
- 최솟값: 2.39789527279, 최댓값: 24.276483594892518.
- Boxplot

- 분포 그래프
3. AMT 데이터셋 준비
2019년 1월부터 2020년 3월까지 각 feature 조합이 829430개씩 있다. 동일한 feature 조합에 대해 기간만 2019년 1월, 2월, 3월, ... 과 같은 방식으로 다르게 하여 AMT 데이터를 모아 array로 만든다.
import numpy as np
amt = np.array(df[['AMT']].values, dtype=np.float32)
data = []
for i in range(829430):
temp = []
for j in range(15):
temp.append(amt[829430*j+i, :])
data.append(temp)
data = np.array(data)
data = data.reshape(data.shape[0], data.shape[1])
data.shape # (829430, 15)
data는 각 feature 조합 829430개에 대해 15개 기간의 AMT가 모여 있는 2차원 array이다. 아래 예에서 맨 뒤의 값들만 log1p 함수를 취해 모은 값이다.
# 데이터 구성 예
[201901 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 311200.0]
[201902 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 605000.0]
[201903 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[201904 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[201905 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[201906 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 139000.0]
[201907 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[201908 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 27500.0]
[201909 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 395500.0]
[201910 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[201911 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 843100.0]
[201912 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[202001 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 168500.0]
[202002 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 10.0]
[202003 '강원' '건강보조식품 소매업' '강원' '20s' 1 1 427510.0]
# LSTM 모델링
이제 데이터를 LSTM 모델에 입력할 형태로 바꿔준 뒤, 모델링을 진행했다. 조금 무식하지만 각 829430개의 feature 조합에 대해 모두 다른 LSTM 모델 그래프를 생성한 후, 예측하는 방식을 택했다.
1. LSTM 데이터 생성
3차원 데이터 형태로 모델에 입력할 데이터의 형태를 바꿔 준다.
# LSTM 데이터 생성
def create_lstm_data(X_data, step):
m = np.arange(len(X_data)-step)
x, y = [], []
for i in m:
a = X_data[i:i+step]
b = X_data[i+step]
x.append(a)
y.append(b)
X = np.reshape(np.array(x), (len(m), step, 1))
Y = np.reshape(np.array(y), (len(m), 1))
return X, Y
2. 모델 구성 및 훈련
각 모델에 대해 300번 학습하도록 하고, 테스트 삼아 이후 1기간만 예측하도록 했다.
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense
from tensorflow.keras.optimizers import Adam
tf.compat.v1.disable_eager_execution()
# 파라미터 설정
n_step = 5
n_features = 1
n_futures = 1 # 지금 단계에서는 사용하지 않음.
n_hidden = 128
n_output = n_features
# EPOCHS = 300
EPOCHS = 50
BATCH = 32
# 학습
def train_lstm(X, y):
K.clear_session() # 그래프 초기화
X_input = Input(batch_shape = (None, n_step, n_features))
X_lstm = LSTM(n_hidden)(X_input)
X_output = Dense(n_output)(X_lstm)
model = Model(X_input, X_output)
model.compile(loss='mse', optimizer=Adam(learning_rate=0.01))
hist = model.fit(X, y,
epochs=EPOCHS,
batch_size=BATCH,
verbose=0)
return model
# 예측
def predict_lstm(x, lstm_model):
model = lstm_model
y_pred = model.predict(x)
return y_pred
그런데 곧 Colab이 멈춰 버렸다.(...) 너무 무식하게 많이 돌렸나 보다... 생각해 보니 어차피 결측치를 10으로 채워 줘서 변화가 없는 기간이 많이 있을 것이라는 생각에, 모든 기간에 대해 기존의 데이터가 똑같으면 모델을 돌리지 않고 이전의 값을 사용하도록 변경(결국 결측치를 채운 값을 사용한다는 의미이다.)했다. 학습 에폭도 50으로 줄였다.
estimates = []
for i in range(len(data)):
if len(data[i]) == 1: # 변화 없으면 그대로 예측
estimates.append(data[i][0])
else:
X_train, y_train = create_lstm_data(data[i], n_step)
model = train_lstm(X_train, y_train)
# 1기간만 예측
X_pred = data[i][-n_step:].reshape(1, n_step, 1) # 예측해야 할 데이터
y_pred = predict_lstm(X_pred, model)[0][0]
estimates.append(temp)
3. 예측 및 결과 확인
기본적으로 4월 데이터만 예측한 결과이다. 7월 데이터 공개 전까지는 데이콘 리더보드 상에서도 4월 데이터에 대해서만 채점이 진행되므로 4월 데이터를, 위와 같은 방식으로 모델링하여 예측했을 때 잘 나오는지 확인하고 싶었다.
예측 템플릿도 위와 같은 방식으로 모든 경우의 수에 대해 만들어 준다. 그리고 예측한 값을 expm1 함수를 취해 스케일을 변환해 준 뒤, 예측 템플릿의 AMT 값에 채워 넣었다. 곧 이전과 똑같은 문제에 봉착했다. 제출해야 할 파일의 양식이 월별, 시도별, 업종별로 예측하는 것이었지만, 내가 모델링을 통해 예측한 값은 그 외의 primary key 피쳐들을 사용해 예측한 것이었다. 실험 차원이었으므로 groupby 시 평균값과 중간값을 활용해 한 번씩 리더보드 상에 제출해 보았다.
결과는... 처참했다. 평균값을 냈을 때 11.xx, 중간값을 냈을 때 12.xx였다. ㅎㅎ...
# 배운 점 및 더 생각해 볼 점
4월 데이터에 대해서만 예측을 진행했는데도 불구하고 안 좋게 나온 까닭을 고민해 보았다.
첫째, 차원의 저주 문제가 발생했다. 기본적으로 데이터에 결측치가 1100만 개다. 피쳐 수에 비해 데이터가 너무 부족하다. 둘째, 결측치를 채우는 과정에 문제가 있었다. AMT 데이터가 정규분포 형태를 띄도록 눈으로 확인해서 10으로 채워주긴 했으나, 너무 naive한 접근일 수 있다. 셋째, 역시나 같은 문제지만, 예측치의 평균값 혹은 중간값을 활용하는 과정에서 문제가 있었을 수 있다. 넷째, (제일 희박해 보이지만) 모델링 과정에서 네트워크 구성 및 파라미터 조정에 있어 충분한 시간을 투자하지 않았다. 네트워크 구성을 달리 하거나(사실 그런데, 이 데이터에 대해 네트워크를 복잡하게 구성한다고 성능이 좋아질 것 같지는 않다.) 옵티마이저, 학습률 등을 조정하면 결과가 달라질 수도 있다.
1. 애초에 제출해야 할 파일에 사용해야 할 피쳐만 시계열 모델링에 활용해 보는 건 어떨까?
2. 결측치를 채우지 말고, 기존 데이터를 최대한 활용해 데이터를 불리는 방법은 없을까? 예컨대, GAN...? VAE...?
3. 네트워크 구성, 파라미터 구성 등을 변경해 보자.
'AI > 제주 신용카드 빅데이터 경진대회' 카테고리의 다른 글
| [4] GAN으로 데이터 늘리기 (feat.행복) (14) | 2020.08.18 |
|---|---|
| [2] Gradient Boosting 알고리즘 적용해 보기 (0) | 2020.07.22 |
| [1] Baseline 이해 및 CANCEL 변수 반영 (0) | 2020.07.16 |